
Step 1 – Understanding consensus as it relates to SEO
Definition: Consensus within the scope of ranking a website refers to what the top websites for any given keyword are currently agreeing upon.
There are two primary aspects of understanding consensus: the overall corpus and the specific headers in each article.
In Eric Lanchere’s recent article on Entities, he proposes that Google uses a mechanism/s to initially rank any given article via entity recognition and placement.
What is an entity?
Definition: An entity is a person, place or thing (keyword) as it is understood by any given model (search engine). More importantly, an entity is also how it relates to other entities.
In other words, an entity is a place on a map that has a general relation to other entities – this is one way search engines understand semantic relationships.
Example: Benjamin Franklin is a person (male) who was a president (position of government), therefore Benjamin Franklin has relational value to other Presidents and so on.
Here’s a great video from 2007 on Google’s YouTube channel regarding entities
How do entities relate to consensus?
Entities are the glue that hold it all together. The mere mention of an entity in an article can lead to consensus or opposition (and for the most part SEOs would prefer to meet consensus).
And what’s very interesting is where entities are mentioned within an article seem to matter.
In Eric’s experiment, he was able to test entity placement in a few key places: title and header positions and dispersed throughout the paragraphs.
If Google prioritizes specific portions of an article to aid in the cost of ranking (especially when initially ranking an article) then we can gather and understand consensus of SERPs easier as well. And if Google has tunnel-vision on what it values when ranking new articles, then focus can be given to entities and their placement throughout the article.
Step 2 – Extracting consensus
With the aid of LLMs (chatGPT, Claude, etc), we can extract and understand the consensus of any given keyword.
To start, let’s Google the term “the best lures for bass fishing”.

I then cntrl+click the top three organic search results (SERPS). Then to extract the headers, I use a chrome extension called SEO Meta in 1 Click (I have no affiliation to them).
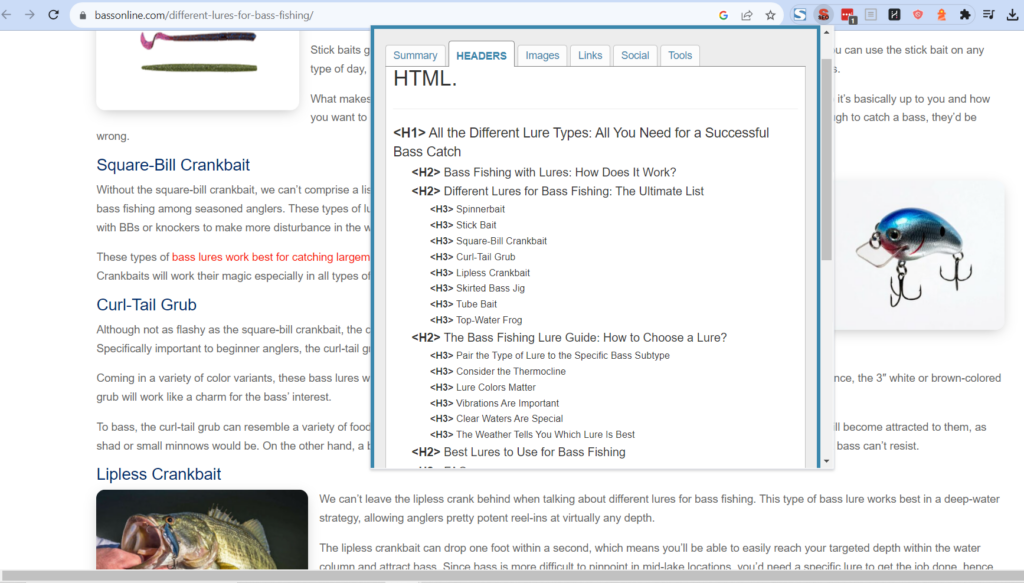
Using chatGPT3.5’s native interface, we can ask for a table of which lures were mentioned for these articles on “the best lures for bass fishing”. And from that, we are given a simple table where consensus can easily be understood.
The conversation with chatGPT can be viewed here. You’ll notice that the LLM has some issue lumping together entities due to specific modifiers. For instance, “tube” and “tube bait” had to be manually mentioned in conversation so that the model would consider them one in the same. Also, at the beginning of the conversation, within the prompt, I requested that brands be disregarded as an attempt to focus on the root entity of type of lure.
And we are left with this table. I’ve bolded those which are mentioned twice or more, all of which can be considered part of the general consensus for the search “the best lures for bass fishing”
| Type of Lure | Mentioned in SERP #1 | Mentioned in SERP #2 | Mentioned in SERP #3 |
|---|---|---|---|
| Swimbait | Yes | Yes | |
| Popper | Yes | ||
| Tube (Tube Bait) | Yes | Yes | |
| Spoon | Yes | ||
| Craw | Yes | ||
| Buzzbait | Yes | ||
| Soft Jerkbait | Yes | ||
| Crankbait | Yes | Yes | Yes |
| Walking Topwater | Yes | ||
| Scented Plastics | Yes | ||
| Beaver Bait | Yes | ||
| Drop Shot Worm | Yes | ||
| Hollow Frog | Yes | Yes | |
| Creature Bait | Yes | ||
| Ned Rig | Yes | ||
| Topwater Minnow | Yes | ||
| Vibrating Jig | Yes | ||
| Coldwater Shad Crank | Yes | ||
| Soft Stickbait | Yes | ||
| Spinnerbait | Yes | Yes | Yes |
| Skirted Jig | Yes | ||
| Plastic Worm | Yes | Yes | |
| Stick Bait (Stickbait) | Yes | ||
| Curl-Tail Grub | Yes | ||
| Lipless Crank | Yes | ||
| Skirted Bass Jig | Yes | ||
| Top-Water Frog | Yes |
Step 3 – Prioritizing consensus
In the above example, if I were writing the article to rank for this specific keyword, I would first identify which lures were mentioned three times.
Crankbait, spinnerbait.
The next step is to identify all entities mentioned twice (prioritizing SERP position #1). In this example, all of the two-time mentioned entities are represented in the postion #1 SERP – so that’s not a concern.
Swimbait, Tube (Tubebait), Hollow Frog, Plastic Worm.
And from that, we’ve identified the order and the specific entities (in this case bass lures) for our article.
Step 4 – How to obtain Hybrid Consensus
The concept of Hybrid Consensus is two-fold: acknowledging the current consensus while providing information gain as supplementary information.
Information gain happens in two primary locations: headers (via entity placement) and in-body (via data not yet represented in any SERP).
Hybrid Consensus via Headers
In the above example of bass fishing lures, we had a surplus of lures mentioned only once. That is not always the case with a given keyword. But because that’s our example, we might as well carry on with it.
The consensus would dictate that the H2 headers for that article are in order (see below screenshot). The green entities are those mentioned in top three SERPs and the teal are those only mentioned in two search results.
Note: the “tube” entity was mentioned as “tube” in SERP #1 and elsewhere mentioned as “tubebait” – I’ve opted to go with the #1 position variant.

The next step is simple. Include every entity (lure) currently omitted that is only represented in the #1 SERP, then move to the #2 SERP, and then the #3 SERP. This prioritizes not only consensus but the order of the entities.
Here’s a Google Doc to see how this shapes up into an article structure.
Does this provide information gain at this step of the process?
Yes and no.
Yes, our article will have more entities then all of the other three SERPs but it is merely compiling the entities of each article.
The key, if possible, is to see if there’s any header-placed entities not yet represented in any of the top three SERPs and could relate to the keyword – and if so, then include those below the consensus entities.
For this specific example, that may be hard to do as they’ve seemingly exhausted every type of lure for bass fishing (but chatGPT will know better).
This is the prompt I asked chatGPT for lures that may have been missing from our list. And sure enough, there are some lures the top 3 SERPs missed – which is information gain for this within the header position. Check the Google Doc to see how I included the information gain headers.
Hybrid Consensus via Paragraph Text
Now we need to consider the corpus of each SERP.
What does the body of text below each header say?
What do they mention?
What do they link to?
From this, we’ll be able to understand how to provide information gain within the bulk of the article (typically through a defined, repeatable structure).
The #1 positioned SERP has a very simple paragraph structure into an affiliate link. Click here to view.
The #2 positioned SERP is very similar but without affiliate links. Click here to view.
The #3 positioned SERP has Key Features, Pros and Cons, then a body of text. Their affiliate links are in the headers. Click here to view.
This next step takes some finesse in regards to structure – your preference is your preference – but the goal is to provide specific information that is included in these SERPs and is not yet included (but would provide value to the reader).
Using an LLM can help. I prefer Claude for this step but unfortunately I cannot link to the conversation for you to view.
This is the prompt I use. I also extract the entire text of each SERP and input it as a txt file (which Claude does automatically).

And this is the LLM’s recommendation.

And that is an excellent start and not bad for a simple prompt.
Now I went a step further and asked, “Write my article section on Crankbaits with your recommendations.”
And this is the reply.

Affiliate links could naturally be added throughout the article in-body at this point.
I typically never use Claude in this manner for writing articles as it would take too long – but it’s great for demonstrating the concept.
Also, be mindful that using LLMs to write the text under the headers using the strategy sometimes leads to text that too closely resembles the competition. I’ve never seen word for word plagiarism – but be careful.
Rinse and repeat for each header. Good to go.
Want More SEO Strategy? Join the newsletter 👇
Closing Remarks
Realize that this keyword example has specifics to it we did not speak of – such as the brands of the lures mentioned. How do they play into the consensus? Do multiple SERPs prefer specific brands? These things matter – and of course using a strategy like this can evoke analysis-paralysis.
But still, this is a strategy that has worked well for me and my clients. It’s repeatable, scalable with the right processes in place, and seems to serve the end-user with high-quality information.
I also believe external links can provide consensus as well – but this is harder to accomplish and more manual then copy+pasting text into LLMs and asking for results.
Disclaimer
Do not use this strategy blindly as my results are no indication of future results you may or may not receive as Google’s algorithm is ever-changing and the nuance between niches/topics/keywords has to be considered.
And for a more formal disclaimer: the strategy of Hybrid Consensus is a theory that I’m currently testing – please use the concepts in this article at your own risk. Everything stated here is for informational purposes only.